今日も遅い時間から始まった、「Geminiで動く図解を作ろう」セミナーに参加して、いくつか面白いSVGアニメーションや図解を作りました。
仕事で使えるかは微妙ですが(^^;)
でも、刺激になりますし、他の人のプロンプトや制作の仕方を見れるのはいい勉強になります♪
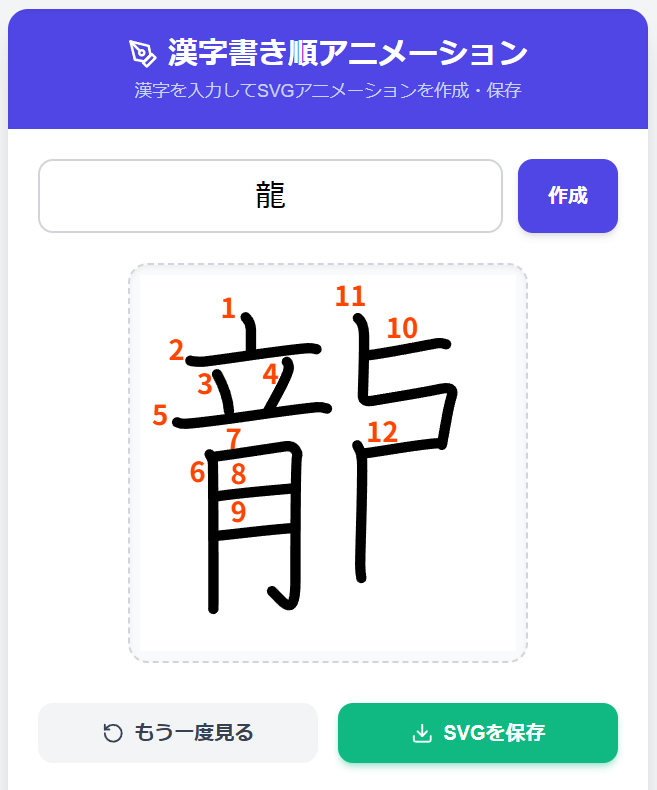


今日も遅い時間から始まった、「Geminiで動く図解を作ろう」セミナーに参加して、いくつか面白いSVGアニメーションや図解を作りました。
仕事で使えるかは微妙ですが(^^;)
でも、刺激になりますし、他の人のプロンプトや制作の仕方を見れるのはいい勉強になります♪
無くてはならないツールになりつつあった音声を文字入力に自動的に変換する仕組み。これが急に動かなくなりました。原因を究明していたら、一昨日から手を付け始めた確定申告作業の自動化作業でした。。こちらは今回のに間に合わなさそうだったのでいったん保留でということで音声入力自動化を復旧したのですが、なんだかんだで4時間かかってしまいました。。
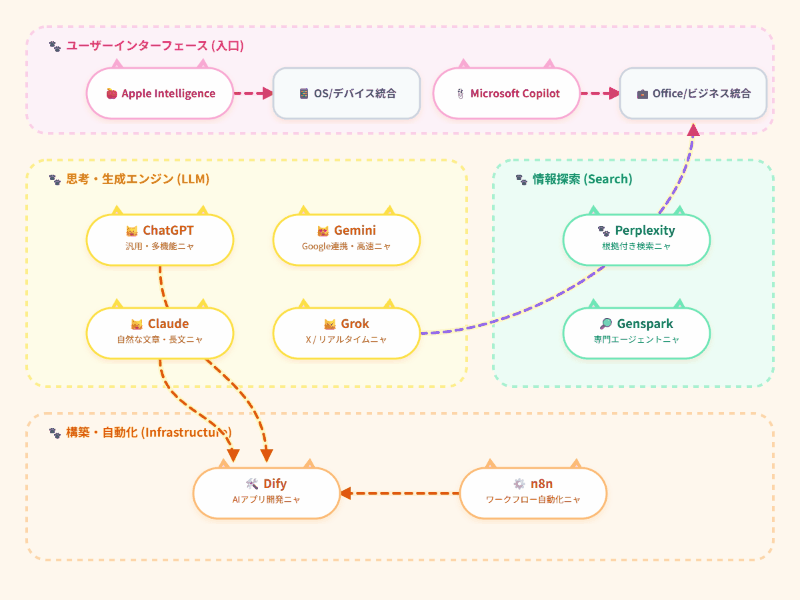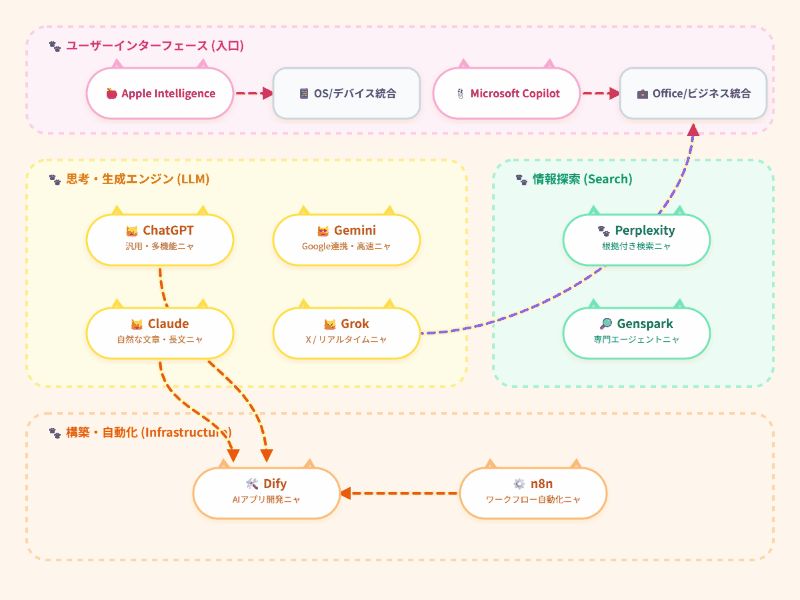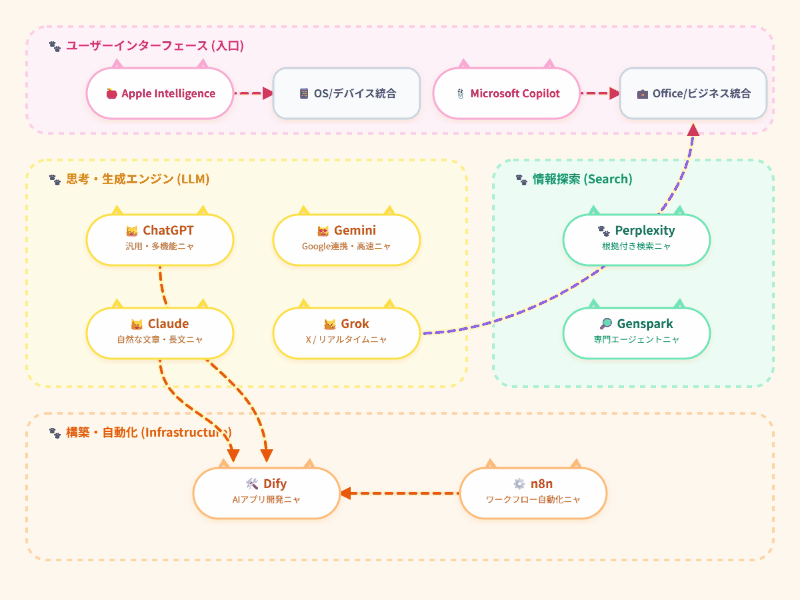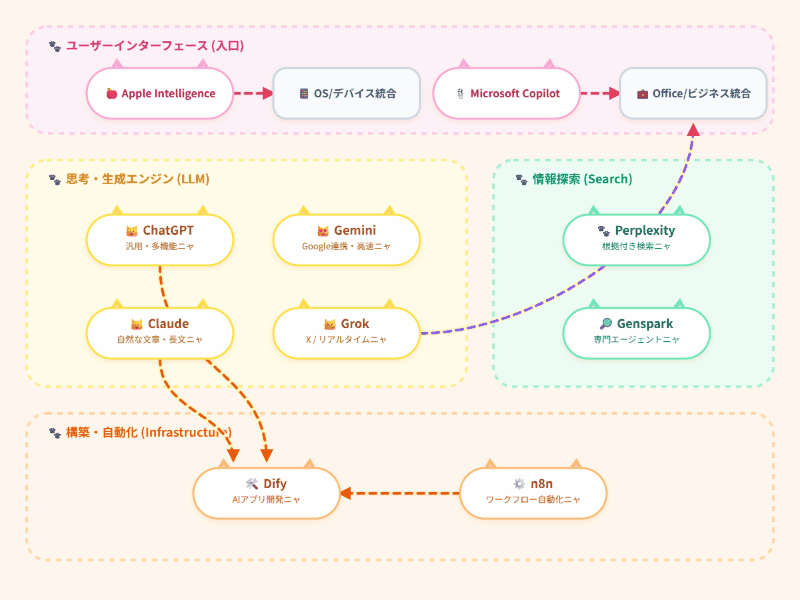
また、今回も記録をGemini作成、ChatGPT編集、私最終校正で作ったのでアップします~(インフォグラフィックスも同様に作りました、なんか1ヶ月前より良くなっている?)

失われた「声」と本陣の再構築―Windows環境におけるAI音声入力復旧の記録
失われた「声」と本陣の再構築
日常の道具が、ある日突然その機能を失う。それはたいてい、大きな事件の顔をしていない。むしろ「ちょっとした掃除」の副作用としてやってくる。
今回の発端は、システムの最適化を目的とした整理だった。不要な仮想環境を削除し、古いライブラリを一掃し、PCを“軽くする”はずの作業。ところが、その代償として長年連れ添ってきた音声入力システムは沈黙した。
起動直後に表示されたのは、「DLLが見つからない」という無機質な一文。それはエラーというより、拒絶だった。
混在するPython、失われた秩序
調査を進めると、PC内部には複数のPythonバージョン(3.12、3.14など)が混在していた。どの個体が主導権を握っているのか、もはや判然としない。
最新の3.14は確かに新しい。しかし、AI開発に必要な外部ライブラリとの互換性はまだ万全とは言えない。一方、以前安定していた環境は、整理の過程で物理的に消えていた。
しかもこのトラブルが起きたのは、仕事が立て込んでいる時期だった。本来なら別の案件に使うはずの時間が、静かに削られていく。気がつけば、4時間。
何も生み出していないようでいて、しかし止まったシステムを前にしては進むこともできない。そんな種類の4時間だった。
「最新」ではなく「本陣」を選ぶ
ここで下した決断は、「本陣の再建」である。流行や最新版を追うのではなく、最も安定性の高いPython 3.11を改めてインストールし、これをシステムの“コア”として再定義する。
土台を決める。まずはそこからやり直す。
遠回りに見えるが、実は最短距離だと経験上わかっている選択だった。
欠落した“筋肉”と、深層からの借用
しかし問題はそれだけではなかった。AIモデルを動かすための“筋肉”ともいえるGPUエンジン(DLLファイル)が欠落していたのである。これがなければ、いくらPythonを整えても動かない。捜索の末、Python 3.14の深層にそのエンジンが眠っていることを突き止めた。
ここで選んだのは、無理に移植することではなかった。3.11の配下に組み込むのではなく、必要な瞬間だけ“借用”する。境界線は守る。しかし、必要なら通路は一時的に開く。この設計思想が、今回の復旧の核心だった。
見えない裏側での再構築
最終的に、バックグラウンドでの隠密起動を担うVBScriptをアップデートした。スクリプトが呼ばれた瞬間、必要なエンジンへの道(パス)を一時的に通し、Python 3.11を明示的に指名して起動する。処理が終われば、その道は静かに閉じる。
「境界線を維持した借用」。
その結果、既存のキーボード連動(Scroll Lock + Endキー)という操作感を一切変えることなく、システムは息を吹き返した。
外から見れば、何も変わっていない。だが内部では、本陣が再編されている。
再点灯するマイクアイコン
再起動後、タスクバーにマイクアイコンが灯った。ただそれだけのことだ。だが、止まっていた流れが戻る瞬間には、わずかな安堵がある。4時間という時間は戻らない。しかし、その4時間で環境は整理され、主従関係は明確になり、次に同じ混乱が起きる可能性は大きく下がった。
これは単なるトラブルシューティングの記録ではない。複雑化した環境を見直し、安定という名の「本陣」を再構築した、小さな戦記である。
そして何より——
忙しいときほど、足元の構造を整える価値はある。沈黙していた「声」は、そう教えてくれた。
今日から作業を開始。。。その前に、レシートのデータ化は簡単なのか。それを悩んだので、Geminiとやり取りしたり、写メったデータを読み込ませて検証などを行いました。
そして、それもGemini作成、ChatGPT監修、最終校正:私で記事を書いたのでアップします!(同様に、インフォグラフィックスをNotebookLMに作ってもらいました)

~確定申告をローカルAIで自動化できるか?実装前にやった「原資料」検証の話~
【1日目】
確定申告の作業は、いまだにどこかアナログな匂いが残っています。レシートを集め、金額を打ち込み、勘定科目を考える。今回はそれを、クラウド任せではなくローカル環境で自動化できないかを検証しました。
目標は「弥生会計に取り込めるCSVを自動生成すること」です。ただし、いきなりコードは書きません。最初にやったのは、もっと地味で重要な作業でした。
1. レシート撮影は本当に“写メ”で足りるのか?
最初の論点はシンプルです。「スマホで撮った写真は、OCRやAIにとって十分な入力なのか?」試してみると、いくつかの課題が見えてきました。
○ 遠景撮影の問題
長いレシートを一枚に収めようとすると、どうしても引いて撮ることになります。すると文字が小さくなり、特に数字の判別精度が落ちます。「8」と「3」の誤認識のような、地味ですが致命的なミスが起こりやすくなります。
○ 折るという選択
そこで考えたのが、レシートを軽く折り、店名と合計金額を物理的に近づけて撮る方法です。これだけで、文字の密度が上がり、読み取り精度はかなり改善しました。
AIに頑張らせる前に、入力側を整える。ここが最初の気づきでした。
2. スキャナという選択肢
さらに検証を進める中で、スマホ撮影よりも安定した方法があることに気づきます。それがフラットヘッドスキャナです。なぜ「スキャンが良い」のか。
・影が出ない
・コントラストが安定している
・傾きが発生しない
さらに、長いレシートや品目の多いものでも、フラットに取り込めます。特に複数商品・1万円超のようなレシートでは、スマホ撮影よりもスキャンの方が明らかに安定していました。
また意外だったのは、最適化されたスキャン画像の方がファイルサイズが小さいケースがあること。ローカルでAIを回す場合、画像サイズはVRAM使用量に直結します。この点でもスキャンは合理的でした。
それから、背景を黒バックにすること。これはいくつかの写メとスキャンデータで確かめたことですが、背景が様々であったり、傾いて撮影したりすると精度に揺れが生じるだけで無く、普通のコピー機だと背景がすべて白になり、境界が曖昧になることでデータサイズが拡大したり、OCR精度が落ちる危険性がありました。こちらも何度かテストを行い、最終的には、黒画用紙を背景にスキャンすることが一番効果的ということが分かりました。
3. 「スタート一回」で終わる設計を考える
スキャンの弱点は「手間」です。蓋を開けて、並べて、閉じて、保存する。そこで、発想を少し変えました。
A3サイズでまとめてスキャンし、その後はプログラムに任せる、という考え方です。スキャン時には複数枚のレシートを同時に取り込んだり、多少傾いていたり。縦横が混ざっていたりしてもいい形で。これならば、1枚ずつスキャンするという手間や面倒くささが軽減され、さらにノイズになってしまう、傾きや90度向きが傾いていて、取り込みに手間がかかってしまうことを防ぐことができる方法です。
1. 複数レシートを並べて一括スキャン
2. Pythonで自動的に輪郭検出
3. 個別レシートごとに自動切り出し
4. 傾き補正・回転
5. フォルダ監視で自動処理開始
人間の作業は「並べてスキャン」だけ。その後は自動で流れるという設計です。
4. まだコードは動いていない
今回のは、まだ実装していません。
やったのは、
・どう撮れば精度が安定するか
・どの入力方式が再現性を持つか
・自動化に向いた原資料とは何か
ということを整理することでした。AIは便利ですが、入力が曖昧なままでは精度は安定しません。また、一次データである画像が高精度であれば、今後、AIやOCR精度が向上したときにより高度な戦略が打てるようになる。そのためにも一次資料はできるだけ手間をかけず、しかし高精度でおきたい。
最初、確定申告作業の自動化作業の中で、写メった画像があれば、それをAIに読み取らせ、会計ソフトに渡すことができるようにすることが自動化作業の肝かなと思っていました。しかし、最初の「画像化」もかなり大事なことなのだと気づきました。結局のところ、「出力の信頼性は、入力の規格で決まる。」これは一連の検討作業において良き収穫となりました。(生成AIとのやり取りに5時間かけました)
実装はこれからですが、こうした、場を整えること。そして、生成AIに何が出来るか。自動化作業とはどういうことなのか。どの段階の精度を上げて、どの段階はコストを払うのか。この確定申告作業の自動化作業は(時間は無い中で)、そういった、私自身の省力化、付加価値を上げることを考えるいい作業となっているかなと思います。
まだ全体の一里塚。「最終的に税理士さんに投げた方が良かった」とはならないよう、頑張っていきたいと思っています。
(作成:Gemini、監修:ChatGPT、最終校正:私)
音声入力自動化作業の構築に味を占めました(笑)
今、GeminiとChatGPTを使って、次の自動化作業を模索しています。(仕事が忙しくて案の検討段階ですが(^^;))
そして第2弾!
やらなきゃいけない「確定申告作業」の一部自動化について。
こちらを、今朝からGeminiとChatGPTに考えてもらい、自動化作業の工程案ができました!(まだやっていない💦)
少し仕事が落ち着き、というよりもう取りかからないとヤバいので(まだレシートの束に手を付けてないです。。)、せっかくなら自動化作業をしてみようかと(笑)
その案を、ルポライター記事風に作ってくれたのでアップします!!
——————————–
AI活用して、自動化作業をやってみた パート2
~確定申告作業に伴う、レシート→会計ソフト入力の自動化~
2026年、確定申告の季節。
毎年恒例の「レシートの山」を前に、今回は趣向を変えることにした。
これまでのPC自作歴と、RTX 4060を積んだPCリソースを使い、このルーチンワークを「自動化の設計訓練」として再構築してみる。
単にツールを使うのではなく、AIをどう制御し、構造化するか。これをGemini及びChatGPTと対話しながら構築したその記録である。
終わりに
「面倒な作業」を、設計の材料に変える。この至上命題を勝ち取るべく、比較検討し、この案ができあがった。
今回作った土台は、今後、領収書PDFや銀行明細の統合へも拡張できるはずだ。
AI活用の成熟度は、使ったツールの数ではなく、どれだけ自分の手で構造を制御できたかで決まる。あとは実際、この工程を行い、本当に自動化、省力化できるか試行錯誤するだけである。楽しみだ。
(作成:Gemini、監修:ChatGPT、最終校正:私)
———————————–
インフォグラフィックスで画像も作ってもらったのでそれも貼り付けます~


前回、音声入力自動化作業の構築をアップしましたが、思い立って、NotebookLMでインフォグラフィックスをさくせいさせてみました!
なかなか面白い出来(笑)
ちなみに、今は少し改良しています。
Endキーは多少日本語入力ソフトも使うため、エラーが起きたりしていました。(ファイル名をキーボード入力していたら勝手に文章が入力されたりとか)
現在は、スクロールキーを押したら音声入力ができるようになり、Endキーを押して入力開始とするというシステムにしています。
これでキーボード入力と音声入力を切り替えて省力化に成功しました!(まだ変換性能はまだまだですが、大満足♪)
今日は、あるセミナーに参加しました。「初心者さん向けGPTsの作り方解説セミナー」というもの。私はChatGPTは無課金で、GPTsは使えないのですが、GeminiのGemに応用できないかなと思い、参加しました。
GPTsは面白いですね!チャット画面で、プロンプトを作り込まなくてもある程度のものが作れる様は面白かったです!
一応、まねしながら作ってみたところ、キャラ作りのGemはできました。そこでゆるかわ風の猫キャラを作って貰いました。


何も指示せず、ある程度やり取りするだけでこんなのができるなんてすごいなって思います♪
さらに、そこで作られたマンガを生成するGPTsをお借りして、4コママンガを生成しました!
実際にはプロンプトの生成で、マンガ生成はNanobanana proを使いましたが、これもいい感じだなと思いました!
内容は、ほぼChatGPTが出した案から適当に選んだだけです。暇つぶしや、ブログ等の賑やかしには最適かなと。
22時からスタートの遅い回でしたが、参加できて良かったセミナーでした♪
<作った4コマ3連作です!>
① クロにゃんのお絵かき

② 線画うまくいったのに色で迷子

③ 深夜テンション神作

↑ これは4コマ目の落ちが悪いなぁと思って、再度プロンプトを作って貰いました。(3,4コマ目は頭のクローバーもなぜか消えていますし。。)そしたら本当に神作が😊

私はイラストとかがまったくできない人なので、この歳になってこんなものが作れるなんて面白いと思いました!
今は深夜1時。。それこそ深夜のノリはそろそろきついですね(笑)
もう1つのキャラ(ChatGPTに名前考えて貰って、ミルにゃんと名付けました!)のも4コマを今度作って貰おうと思っているので作ったらアップしたいと思います~

最近、AIを活用を始めているのですが、非常に入力文字数が増えてきたこともあり、音声入力自動化を検討してみました。
結果的にこの週末を潰す勢いでやったんですけれども、なかなか面白かったので、それをジェミニにまとめさせましたのでアップします。結果的にこの週末を潰す勢いでやったんですけれども、なかなか面白かったので、それをジェミニにまとめさせましたのでアップします。(ちなみにこの冒頭部分は音声入力しています。めっちゃ楽♪)
(画像もGeminiの画像生成を使いました。日本語が(^^;))
【最終技術報告書】思考直結型・ローカルGPU音声入力システム構築全記録
1. システム概要と達成成果
本プロジェクトは、タイピングによる肉体的負荷(腱鞘炎リスク)を排し、思考を遅延なくテキスト化することを目的とした、完全ローカル完結型の音声入力システムである。
2. 使用機材およびソフトウェア構成(Tech Stack)
ハードウェア
ソフトウェア・ライブラリ
3. 具体的な構築手順(エンジニアリング・ログ)
手順1:Python環境と依存ライブラリの整備
Python 3.14環境下で、GPUを駆動させるための特殊な設定を行った。特に最新環境ゆえのDLL読み込みエラーを回避するため、コード内で直接ライブラリパスを通す処理を実装した。
Python
# NVIDIAライブラリのパスを強制的に通す(RuntimeError対策)
os.environ[“PATH”] += os.pathsep + os.path.join(sys.prefix, ‘Lib’, ‘site-packages’, ‘nvidia’, ‘cublas’, ‘bin’)
os.environ[“PATH”] += os.pathsep + os.path.join(sys.prefix, ‘Lib’, ‘site-packages’, ‘nvidia’, ‘cudnn’, ‘bin’)
手順2:ENDキー・トリガー制御の実装
「無変換キー」等のシステム標準キーはIME(ATOK等)と干渉するため、物理的に独立した「ENDキー」をトリガーに採用。keyboard.is_pressed を用いた永続ループにより、キーの状態をミリ秒単位で監視する仕組みを構築した。
手順3:解析と自動貼り付けのパイプライン
手順4:常駐化(サイレント起動)の設定
コマンドプロンプトを表示させずにバックグラウンドで動作させるため、VBScript(.vbs)を作成。Windowsの shell:startup に登録することで、OS起動時に自動で「音声入力待ち受け状態」になるよう設定。
4. 主要なトラブルシューティング記録
5. 結論
本システムは、18時間の構築時間と、のべ40回以上のコード改修、そして5万字に及ぶデバッグ打鍵を経て完成した。これにより、キーボード入力という物理的制約から思考が解放され、AIとの対話成熟度は「自律的制御(レベル5)」の段階へと到達した。
なかなか面白いまとめではないでしょうか。今、小説家バージョンでまとめさせているのもあるので、できたらアップします。
最近、ChatGPTやGemini使って、AIと対話したり、仕事の効率化のため使い始めています。さらに、情報漏洩やAIのさらなる使いこなしのため、ローカルAIの導入を考えました。
せっかくなので、そのやり方をGeminiにも聞きながらやりました。その過程を先ほどアップしましたが、Gemini版もまとめさせたのでここにあっぷします。
ここまでの対話は、技術的な試行錯誤から「知能の選別」という戦略的なフェーズへと進む、非常に見応えのあるプロセスでした。
ブログ読者(特に機密情報を扱う専門職や個人開発者)を想定し、WordPressのブロックエディタにそのまま貼り付けられる「テキスト形式」でまとめました。また、最後には次のスレッドで「即座にコンテキストを同期」するための高精度プロンプトを添えます。
タイトル案:【実践】ローカルAI導入記:機密を守りつつ「自分専用の知能」を構築する4つのステップ
「AIを仕事に活用したい。しかし、クラウドに機密データや極めてプライベートな記録を投げるのは抵抗がある」
そんなジレンマを解決する手段が、自分のPC内で完結する「ローカルAI」です。今回、数日間にわたる試行錯誤を経て、実用的なローカル環境を構築しました。本記事では、技術的なハードルをどう乗り越え、どのモデルを選び、どう運用すべきか、その全プロセスを4つの論点に整理して公開します。
結論から言えば、最新のノートPC(GPU:RTX 4060等)があれば、8B(80億パラメータ)クラスのモデルは驚くほど快適に動作します。
【検証のポイント】
「どのモデルが一番賢いか」という問いには、用途による使い分けが答えになります。今回、以下の3つを「三種の神器」として配備しました。
AIエンジンを直接叩くのではなく、UI(ユーザーインターフェース)を挟むことで、AIのポテンシャルを引き出せることが分かりました。
今回の対話を通じ、私の現在地は「単なるツール利用者」から「AI環境の設計・評価者」へと進化しました。
ローカルAIは、一度環境を整えてしまえば「通信不要・無料・プライバシー完結」の最強のパートナーになります。設定の壁はありますが、それを乗り越えた先には、自分だけに最適化された「知能の書庫」が待っています。
それぞれの特色が出ています。こうしたAI使いこなしを「AI活用成熟度」というそうで、こちらもできれば進化させていきたいな、導入したローカルAIが役に立てばなって思っています😊
最近、ChatGPTやGemini使って、AIと対話したり、仕事の効率化のため使い始めています。さらに、情報漏洩やAIのさらなる使いこなしのため、ローカルAIの導入を考えました。
せっかくなので、そのやり方をChatGPTに聞きながら昨日、導入してみました。その過程でいろいろ聞いたのをまとめましたのでここにあっぷします。
了解しました。
このスレッド全体を「思考の記録として読めるブログ記事」に再構成しつつ、次の検討スレッドに自然につながるプロンプトまで含めて整理します。
以下はそのままWordPressに貼り付けられるプレーンテキストです。
(見出しはWordPress側で h2 / h3 に変換しやすい形にしています)
― 私が今、どこまで来ていて、どこへ進もうとしているのか ―
生成AIが急速に普及する中で、「ChatGPTを使っている」「業務で活用している」という言葉の中身は、人によって大きく異なるようになりました。
クラウドAIを便利なツールとして使う段階から、自分の業務環境にAIをどう組み込むかを考える段階へ進むと、自然と「ローカルAI」という選択肢が視野に入ってきます。
本記事は、これまでの対話を整理しながら、
という4つの論点を軸にまとめたものです。
単なる技術紹介ではなく、「実務者が、自分の仕事と照らし合わせてどう考えるか」という視点で書いています。
まず最初に整理すべき点は、「ローカルAI」と言っても研究者レベルの環境構築は必須ではないという事実です。
現在のローカルAI活用は、以下のような前提に立っています。
特に行政書士・ファイナンシャルプランナーのような文書中心業務では、
画像生成や動画生成ほどの計算資源は不要です。
ローカルAIを検討する理由は、多くの場合次の3点に集約されます。
これは「ChatGPTが不満」という話ではありません。
むしろ、使い込んだからこそ見えてくる次の段階です。
つまり、
ローカルAIは「先端を追いかける人」のものではなく
「業務を安定させたい人」のための選択肢
だと言えます。
ローカルAIモデルを選ぶ際に、最初に決めるべきことは次の3点です。
「何でもできる万能モデル」は存在しません。
用途ごとに役割分担させるという発想が現実的です。
ChatGPTに近い「会話の感覚」をローカルで再現しやすいモデルです。
特に検討メモ・仮説整理には相性が良い。
「それっぽい日本語」ではなく、
実務で使える日本語を求める場合に有力です。
重いモデルを常用する前に、
「まず考えを吐き出す」役割として有効です。
ローカルAIが敬遠されがちな理由は、
環境構築が難しいからではなく、情報が断片的だからです。
実務者にとって重要なのは、
「最短距離で、壊れにくい構成」を選ぶことです。
Ollamaは、ローカルAIを扱う上でのランタイム兼管理ツールです。
「DockerやPython環境を一から組む」必要はありません。
実務で重要なのは、性能よりもUIの安定感です。
Chatboxを使うメリットは、
という点にあります。
結果として、
頭の使い方はChatGPT時代のまま、
裏側だけローカルに置き換える
という移行が可能になります。
一般的なAI活用成熟度を整理すると、以下のように分類できます。
この対話から推測するに、
私はLv3を安定して使いこなし、Lv4に踏み込もうとしている段階です。
特徴的なのは、
点です。
次の段階に進むために必要なのは、新しいモデルではありません。
つまり、
AIを「人材配置」する感覚です。
本当はもっと長いのですが、「ブログに載せるようとしてまとめて」とまとめてもらったものが上記のものです。この間まで自分で考えて作っていたのが。。。
これからはこんな感じで記事も更新できたら💦いいと思ってます。
久しぶりにブログをアップしています💦
この1年あまりも勉強やら活動やらしてないわけでは無かったのですが(^^;)
ところで。今月、ファイナンシャルプランナー仲間との勉強会で「デジタル遺品、デジタル終活」について私が講師として資料作成、勉強を行うことになり、今作成進めているところです。
昨年の今頃と大きく違うのは、生成AIを活用した情報収集と資料作成補助ですね。チャットGPTはもちろん、この間ノートブックLMやジェミニの使い方入門も学んだのでさっそく活用し始めています。
この記事では、Geminiを使って「デジタル遺品とデジタル終活」について、FPが知っておくべきことや役割についてストーリーブックを作ってもらったのでアップします!なかなか面白い内容だなと思います。(これも勉強会で紹介予定です)